Asked in: AMAZON
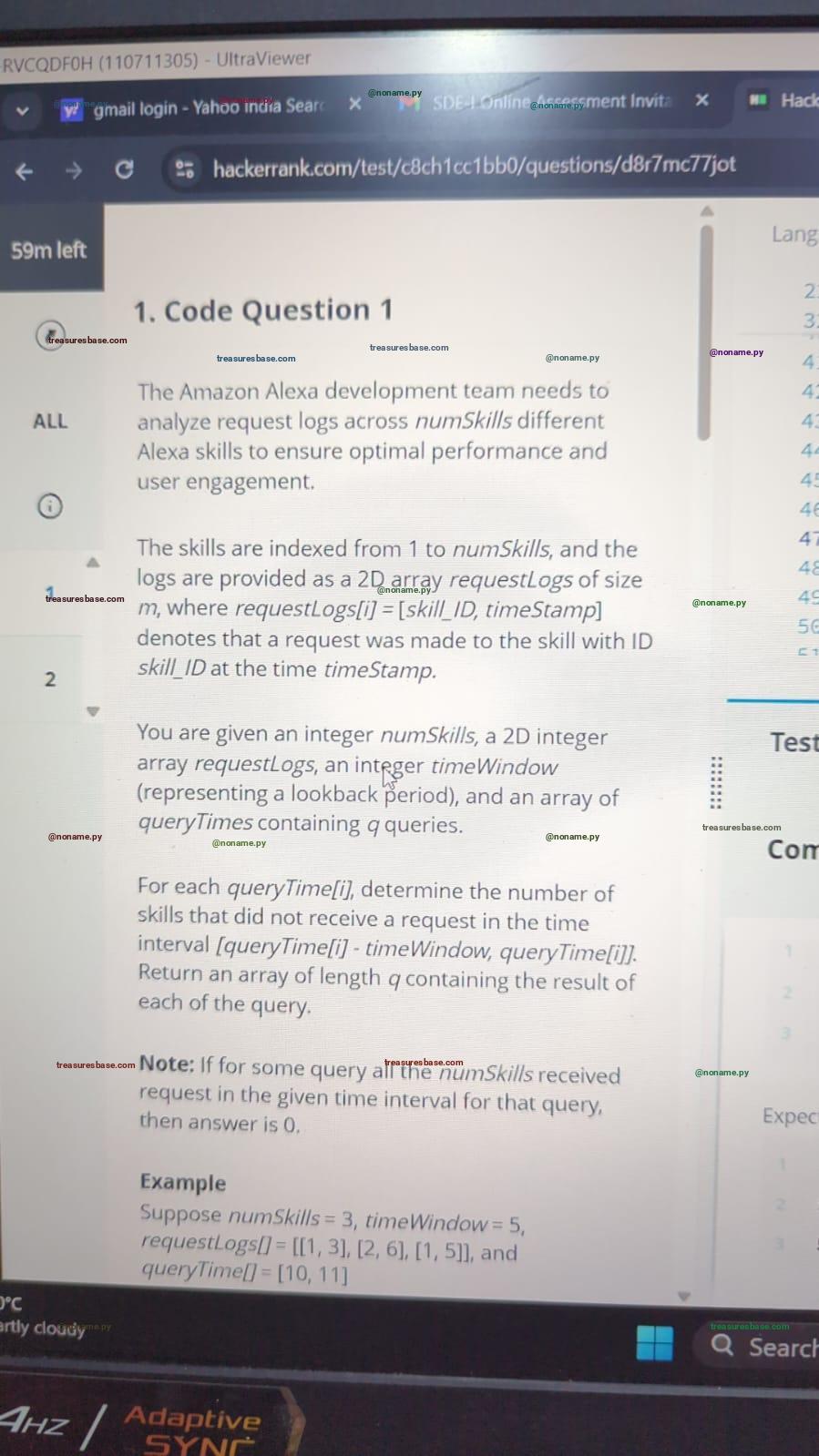
Image of the Question

All Testcases Passed ✔
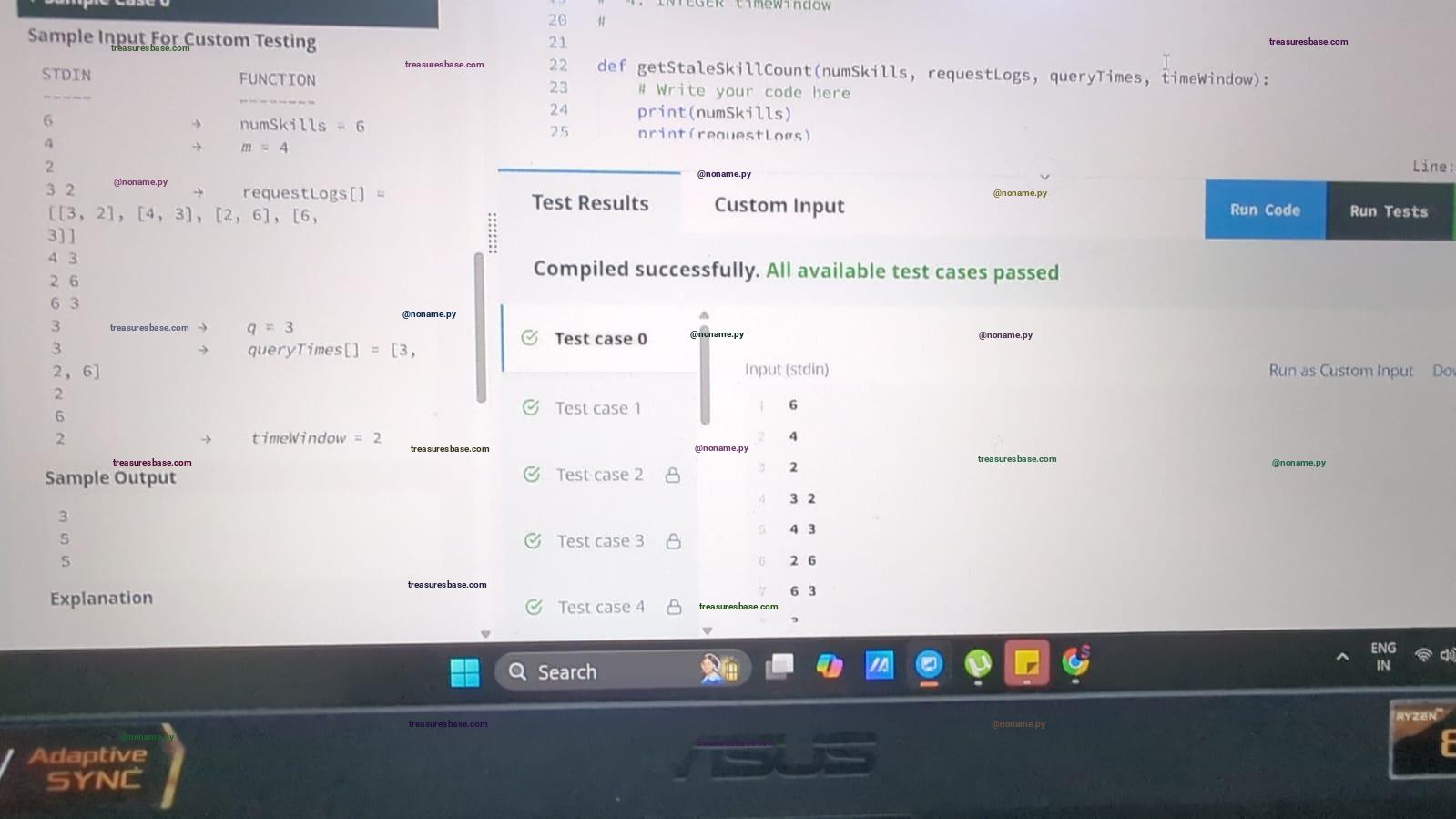
Solution
def getStaleSkillCount(numSkills, requestLogs, queryTimes, timeWindow):
n = len(queryTimes)
answer = [0 for i in range(n)]
arr = [(i-timeWindow,i, idx) for idx, i in enumerate(queryTimes)]
// ... rest of solution available after purchaseExplanation
```
To solve this problem, you need to analyze a series of queries, where each query asks how many Alexa skills did not receive any requests within a certain recent time window. The input consists of a set number of skills, a log of requests indicating which skill was requested at what time, a time window defining the lookback period for each query, and a list of query times.
Understanding the problem deeply is the first step. The logs provide discrete points in time when each skill was requested. For each query time, you want to determine which skills had no requests within a defined interval ending at that query time. This requires checking, for each skill, if there exists at least one request timestamp that falls within the lookback interval [queryTime[i] - timeWindow, queryTime[i]].
A naive approach might be to iterate over all logs for every query and check if any request for a skill lies in the required time window. But this approach would be inefficient, especially if the number of queries and logs is large, leading to a time complexity that could be O(m*q) where m is the number of logs and q is the number of queries.
To handle this efficiently, consider the following approach:
1. **Organize Logs by Skill:**
Group all request timestamps skill-wise. This can be done by creating a mapping from skill IDs to sorted lists of timestamps at which requests were made to those skills. Sorting each skill’s timestamps will allow for efficient interval queries later.
2. **Efficient Interval Search with Binary Search:**
For each query and for each skill, you need to quickly check if there is any timestamp within the time window. Since the timestamps are sorted, you can use binary search to find the earliest timestamp in the list of a skill that is >= queryTime[i] - timeWindow. If this timestamp also falls within the time window, then that skill received a request in that interval. If not, it means the skill had no requests during that period.
3. **Handling Multiple Queries:**
Since you have multiple queries, repeating this binary search for each skill per query could still be costly if done naively. However, with sorted arrays and binary search, the complexity per skill per query becomes O(log m) rather than O(m). Given that you have numSkills skills, the worst-case complexity becomes O(numSkills * q * log m), which can be acceptable for reasonable input sizes.
4. **Preprocessing and Indexing for Faster Access:**
Since queryTimes can be arbitrary and numerous, another approach to speed things up involves preprocessing the logs globally. For example, you might preprocess all logs by sorting them based on timestamps, and use a sliding window or two-pointer approach to quickly identify which skills had requests in any particular time window as queries progress in increasing order of queryTime. This avoids repeated binary searches for overlapping windows.
5. **Sliding Window / Two-Pointer Technique:**
By sorting the queries in ascending order and processing them one by one, you can maintain a sliding window over the request logs. As you move from one queryTime to the next, you slide the window of requests to cover [queryTime[i] - timeWindow, queryTime[i]]. For each sliding window, maintain a count of how many times each skill appears in the window. The count of skills without requests is numSkills minus the count of skills that appear at least once.
6. **Data Structures for Tracking Counts:**
To efficiently update and query the number of skills active in the current window, use a frequency map or array. When a request enters the sliding window, increment that skill’s count; when a request leaves, decrement the count. Keep track of how many skills currently have zero counts (meaning no requests in the current window).
7. **Answering Queries:**
For each query, after adjusting the sliding window, return the number of skills with zero counts.
8. **Edge Cases:**
- If all skills have requests in the window, answer is 0.
- If no requests fall within the time window for a query, answer is numSkills.
- Handle cases where logs might be empty or queries lie outside the range of timestamps.
In summary, the main idea is to leverage sorted logs and queries, and to use efficient data structures and algorithms like binary search or sliding windows to avoid redundant computations. By preprocessing data skill-wise or globally and maintaining frequency counts as the window slides, you can respond to each query in near constant or logarithmic time rather than scanning all logs repeatedly.
This strategy balances between time and space complexity, making it feasible to handle large numbers of skills, logs, and queries efficiently while providing accurate counts of skills without requests in any given time window.
```