Asked in: SALESFORCE
Image of the Question



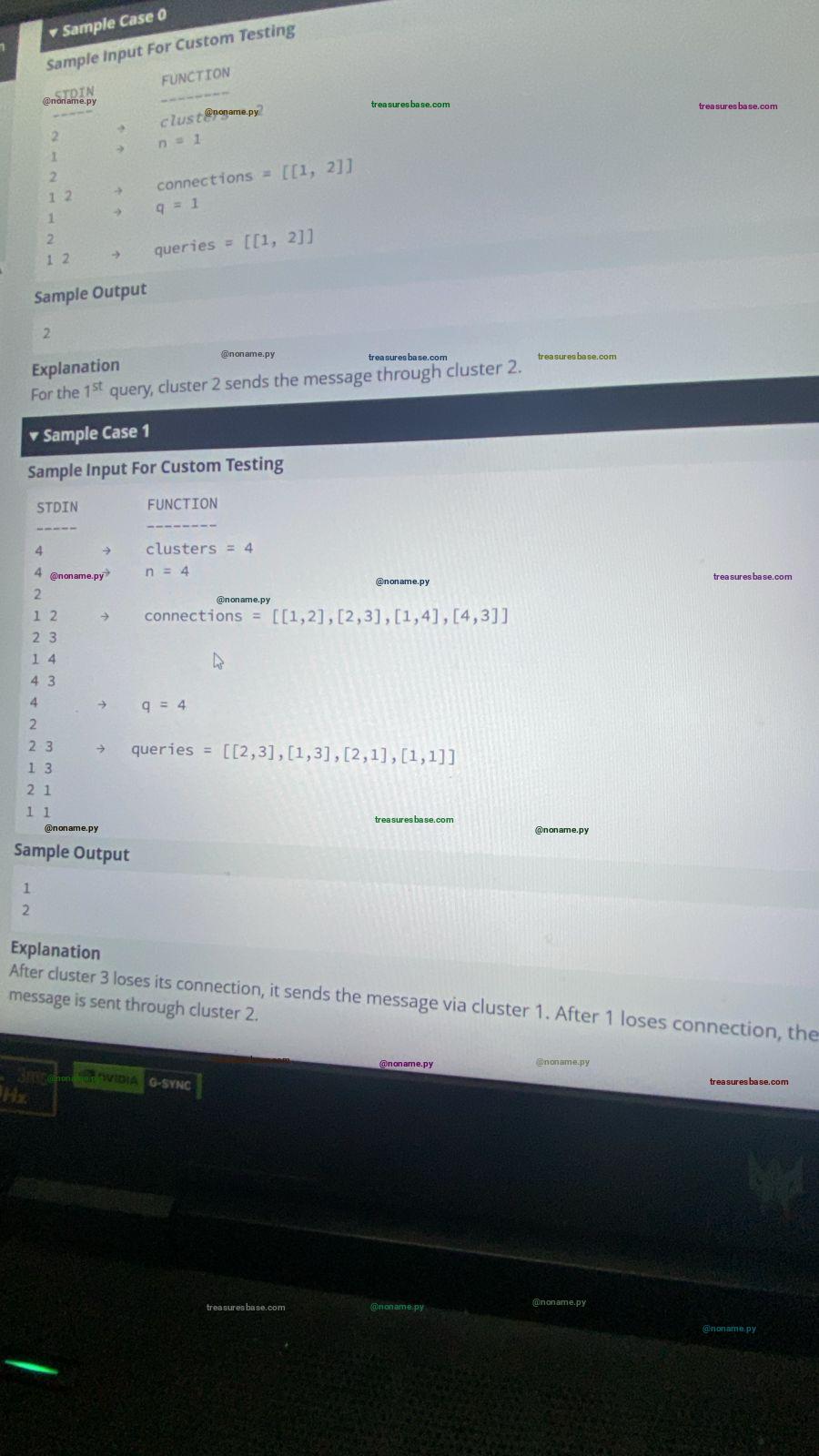
All Testcases Passed ✔

Solution
from collections import defaultdict, deque
import heapq
def getAssignedClusters(clusters, connections, queries):
h = defaultdict(set)
// ... rest of solution available after purchaseExplanation
```
To approach this problem, start by understanding the structure and constraints: We have clusters connected by communication links forming support networks (connected components). Each cluster can be active or offline. When a cluster goes offline, it no longer resolves cases itself, and cases directed to it should be resolved by the active cluster with the lowest ID in the same connected support network. If no active cluster remains in that network, cases are unresolved.
Step 1: Model the Problem as a Graph with Connected Components
The clusters and their interconnections form an undirected graph. Clusters connected directly or indirectly belong to the same connected component or support network. The key observation is that queries relate to clusters within their respective components.
Step 2: Identify Connected Components
To efficiently answer queries about clusters in the same support network, first identify connected components using a suitable data structure or algorithm like Disjoint Set Union (DSU) or Union-Find. This will help quickly find which clusters belong together.
- Initialize each cluster as its own parent in DSU.
- Union connected clusters based on the given connections.
- After processing all connections, each cluster’s component can be identified by its root or leader.
Step 3: Track Active Clusters in Each Component
Initially, all clusters are active. The problem requires tracking which clusters go offline. We need to quickly determine the lowest active cluster ID in a component at any moment.
- For each component, maintain a data structure to keep track of currently active clusters.
- Since the lowest ID is needed, a balanced structure supporting min queries is suitable (e.g., balanced BST, heap, or a balanced segment tree).
- However, since cluster IDs are integers, specialized data structures like segment trees, Fenwick trees, or balanced BSTs (e.g., TreeSet in Java) are options. Alternatively, storing the active clusters in a balanced ordered set for each component works.
Step 4: Handling Offline Operations (Query Type 2)
When a cluster goes offline, it must be removed from the active set of its component.
- Find the component root of the cluster.
- Remove the cluster ID from that component’s active set.
- Removing must be efficient, as the number of queries can be large.
Step 5: Handling Case-Assignment Queries (Query Type 1)
When a case is assigned to a cluster, find the lowest active cluster in its component.
- Find the component root of the cluster.
- Query the active set for that component to get the minimum cluster ID.
- If no active clusters remain, return -1.
Step 6: Initialization and Data Structures
- Initialize DSU for clusters and merge connected clusters.
- For each component, create a balanced data structure containing all active clusters initially.
- Initially, all clusters are active and inserted into their component’s active set.
Step 7: Edge Cases and Constraints
- Some clusters may be isolated (no connections), forming single-node components.
- Offline operations can make components empty; then queries should return -1.
- Input constraints (up to 10^5 clusters, 2×10^5 queries) require efficient operations—amortized O(log n) for insertion, deletion, and minimum retrieval.
Step 8: Summary of Query Handling
For each query:
- If it’s a failure query (type 2), remove the cluster from its component’s active set.
- If it’s a case-assignment query (type 1), output the minimum cluster ID from the component’s active set or -1 if empty.
Step 9: Optimizations and Implementation Notes
- DSU find operations can be optimized with path compression.
- Union operations should keep track of which clusters belong to which component.
- Active sets could be stored in arrays or maps keyed by component root.
- Keep track of component sizes to optimize merges (union by size/rank).
- Since cluster IDs are unique and limited, a balanced BST or segment tree with lazy propagation can be used to manage active sets efficiently.
This approach leverages graph connectivity concepts and dynamic set operations to efficiently answer queries about active clusters in connected components, meeting the problem’s constraints and requirements.
```