Asked in: AMAZON
Image of the Question




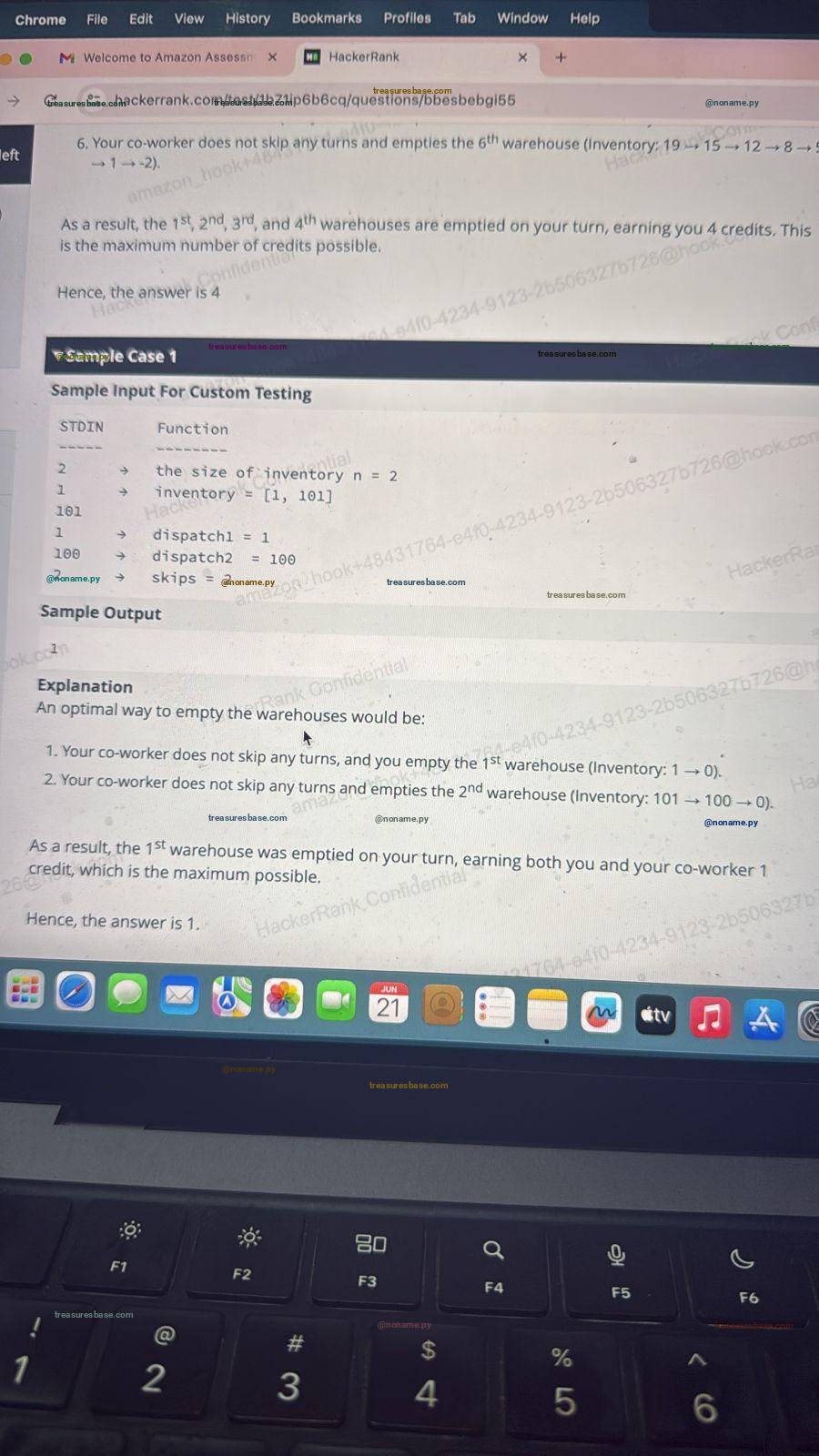
All Testcases Passed ✔
Solution
vector<long> getMinConnectionCost(vector<int> warehouseCapacity, vector<vector<int>> additionalHubs) {
int n=warehouseCapacity.size();
int q=additionalHubs.size();
// ... rest of solution available after purchaseExplanation
```
To approach this problem efficiently, it is important to understand the structure and behavior of the logistics network as described. You are given a list of warehouses, each located at a position from 1 to n with increasing storage capacities. Every warehouse must be connected to a hub that is located at the same position or to the right of its current position. The main constraint is that the hub must be located at a position ≥ the warehouse’s position.
For each query, two additional hubs are temporarily activated at specific warehouse positions (hubA and hubB), and along with the permanent hub at position n, they provide three potential destinations to which a warehouse may connect. The warehouse chooses the hub that is located at or beyond its position and minimizes the connection cost, which is defined as the difference between the capacity of the hub and the warehouse itself.
Understanding this setup, the goal of each query is to compute the minimum total cost for all warehouses to connect to their closest feasible hub (among hubA, hubB, and n).
Let’s break down the problem and outline a methodical strategy:
1. **Leverage the Non-Decreasing Property**:
The fact that warehouse capacities are in non-decreasing order makes it easier to make decisions about which hub to connect to. Because the positions are ordered, and capacities do not decrease, the cost between two positions is always non-negative and directly tied to their relative positions.
2. **Identify and Sort the Hub Positions for Each Query**:
For every query, you are given two temporary hubs (hubA and hubB). Since the hub at position n is always available, each warehouse will choose the nearest hub at or beyond its position. That means, for each query, you need to know the list of available hubs: [hubA, hubB, n], and these should be sorted to facilitate binary search. Sorting these hubs helps you quickly determine the first hub that is located at or beyond the warehouse's position.
3. **Efficient Per-Query Processing via Prefix Sums**:
Given the large constraints (up to 1e5 queries and 1e5 warehouses), a brute force check per query would be too slow. Therefore, you must preprocess as much as possible. This involves using prefix sums and range segmentation. You break the list of warehouses into ranges:
- From position 1 up to just before hubA.
- From hubA up to just before hubB.
- From hubB up to just before n.
- hubA, hubB, and n are hubs themselves and incur no connection cost.
Each range will be assigned the corresponding hub it should connect to — the first hub that lies at or beyond the starting position of the range. Since positions and capacities are ordered, you can precompute partial sums of capacities to speed up the calculation of costs for each range.
4. **Calculate Range Costs Using Precomputed Sums**:
Once you segment the warehouse list into contiguous ranges based on which hub they would connect to, you can compute the total cost per range using prefix sums. For each warehouse in a range connecting to hub at position j, the cost is warehouseCapacity[j] - warehouseCapacity[i], summed over the range. This can be simplified using the sum of the values in the range and the number of elements multiplied by the target hub capacity. Efficient prefix sum usage allows you to compute these in constant time per range.
5. **Avoiding Redundant Computation**:
Since each query is independent and the only difference between them is the hub positions, you do not need to recalculate static information like prefix sums. You compute this once at the beginning and reuse it for all queries. Moreover, because capacities are non-decreasing, you can use binary search to identify the cutoffs where one hub starts to be the best choice over the previous one. This makes the per-query work very efficient, reducing it from linear to logarithmic where possible.
6. **Edge Handling**:
Special cases like warehouses already being hubs (hubA, hubB, or n) incur zero cost and should be skipped in the summation. Also, if the hubs are placed in a way that the transition from one to the next skips over some warehouses, this needs to be handled in the segmentation logic.
7. **Final Assembly**:
For each query, process the segments:
- Compute the connection cost for each range by using the appropriate hub.
- Add the results to get the total cost for the query.
- Append the result to the output list.
By leveraging sorting, binary search, prefix sums, and efficient segmentation based on hub positions, you can compute each query in a time-efficient manner despite the large constraints. The critical insight lies in understanding that the grid is ordered and that the problem can be reduced to working over segments where a single hub is optimal, which allows for precomputed data to be reused across queries.
```