Asked in: No companies listed
Image of the Question
All Testcases Passed ✔
Solution
def findLongestLength(fullString):
h = {}
for idx,i in enumerate(fullString):
if i not in h:
// ... rest of solution available after purchaseExplanation
```
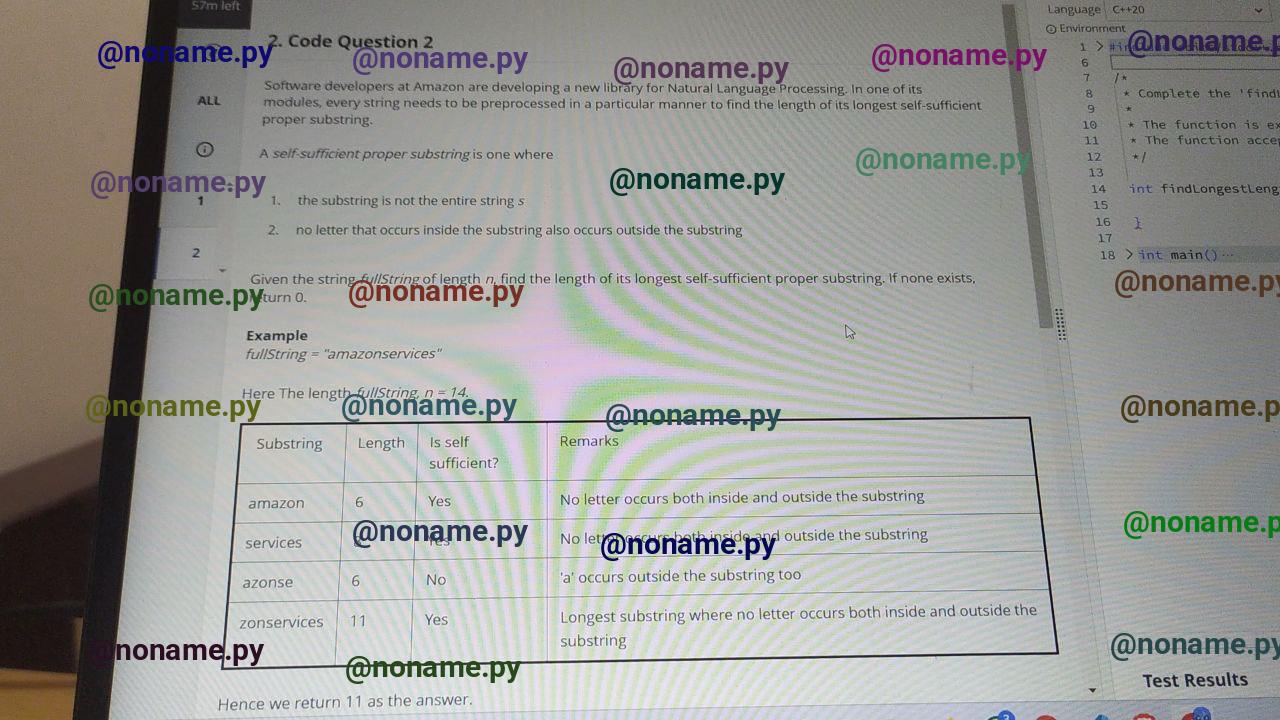
To approach the problem of finding the longest self-sufficient proper substring, it's essential to first thoroughly understand the definitions and constraints given. The problem introduces a few key concepts that will guide how we think about solving it, even before diving into any implementation. Let's walk through a structured way to think about solving this step-by-step.
First, let's understand what is meant by a "self-sufficient proper substring". A substring is any contiguous sequence of characters within a string. A proper substring, however, is one that is not equal to the entire string itself. The term "self-sufficient" is more unique in this context and is defined specifically here: a substring is self-sufficient if every character in it is exclusive to it – that is, no character in this substring appears elsewhere in the original string, either before it starts or after it ends.
This definition introduces a dual requirement: you must identify all substrings that are not equal to the original string, and then filter those down to only those in which every character is completely contained within the substring, without any duplicates in the remainder of the string.
To begin solving this, you need to explore all possible substrings of the input string, taking care to exclude the entire string itself. This suggests a nested loop approach where you vary the start and end indices to generate all substrings. However, the trick lies not in generating substrings but in determining whether each one meets the self-sufficiency condition.
To check whether a substring is self-sufficient, you must determine if the characters within it are exclusive to it. That means none of those characters can appear either before the substring starts or after it ends. So, for each substring defined by a starting index and an ending index (exclusive), you must examine the parts of the original string that lie outside that window: one from the beginning to just before the start index, and the other from the end index to the end of the string. You must ensure that there is no overlap between the set of characters in the substring and the set of characters in these two outside parts.
Thinking about efficiency, the brute-force way of checking every substring and then scanning the prefix and suffix outside the substring for character overlap might be sufficient for short strings, but could become inefficient for longer strings. But for now, the goal is to build a correct solution before considering optimization.
When you think of substring generation, a double-loop structure comes to mind: one loop for the starting index and one for the ending index. Each time, you form the substring and compare its character set with that of the remaining parts of the string. If the sets do not intersect, that substring is self-sufficient. Among all such valid substrings, the one with the maximum length is your answer.
You’ll need a strategy to keep track of the length of the longest valid substring found. That’s a typical pattern in search problems — use a variable to store the maximum and update it whenever you find a longer valid candidate.
There’s also value in thinking about how to make these character comparisons efficient. Since you need to compare sets of characters, using data structures like sets makes sense because set operations (like intersection) are fast and expressive.
One important edge case is to ensure you don’t consider the full string, as the problem specifies that the substring must be proper. Also, note that if no self-sufficient substring exists (i.e., every possible substring shares at least one character with the rest of the string), your final answer should be zero. That means you need a reliable fallback mechanism in your logic when no valid candidates are found.
Overall, your approach should involve three key components: generating all possible proper substrings, checking each one for self-sufficiency by examining character usage across the full string, and maintaining the maximum length encountered. Once this conceptual framework is working and giving correct results, you can then begin to think about how to optimize certain aspects, like avoiding recomputation of character sets for overlapping ranges, or early exits when a substring clearly can't be valid.
The important part is to focus on building up the correct logic before worrying about performance. Understand what makes a substring self-sufficient in terms of character exclusivity, and think about the tools or data structures that can help you check that efficiently. Keep a close eye on string boundaries and character overlaps, and systematically evaluate all possible substrings while applying the self-sufficiency test.
```