Asked in: COGNIZANT
Image of the Question


All Testcases Passed ✔
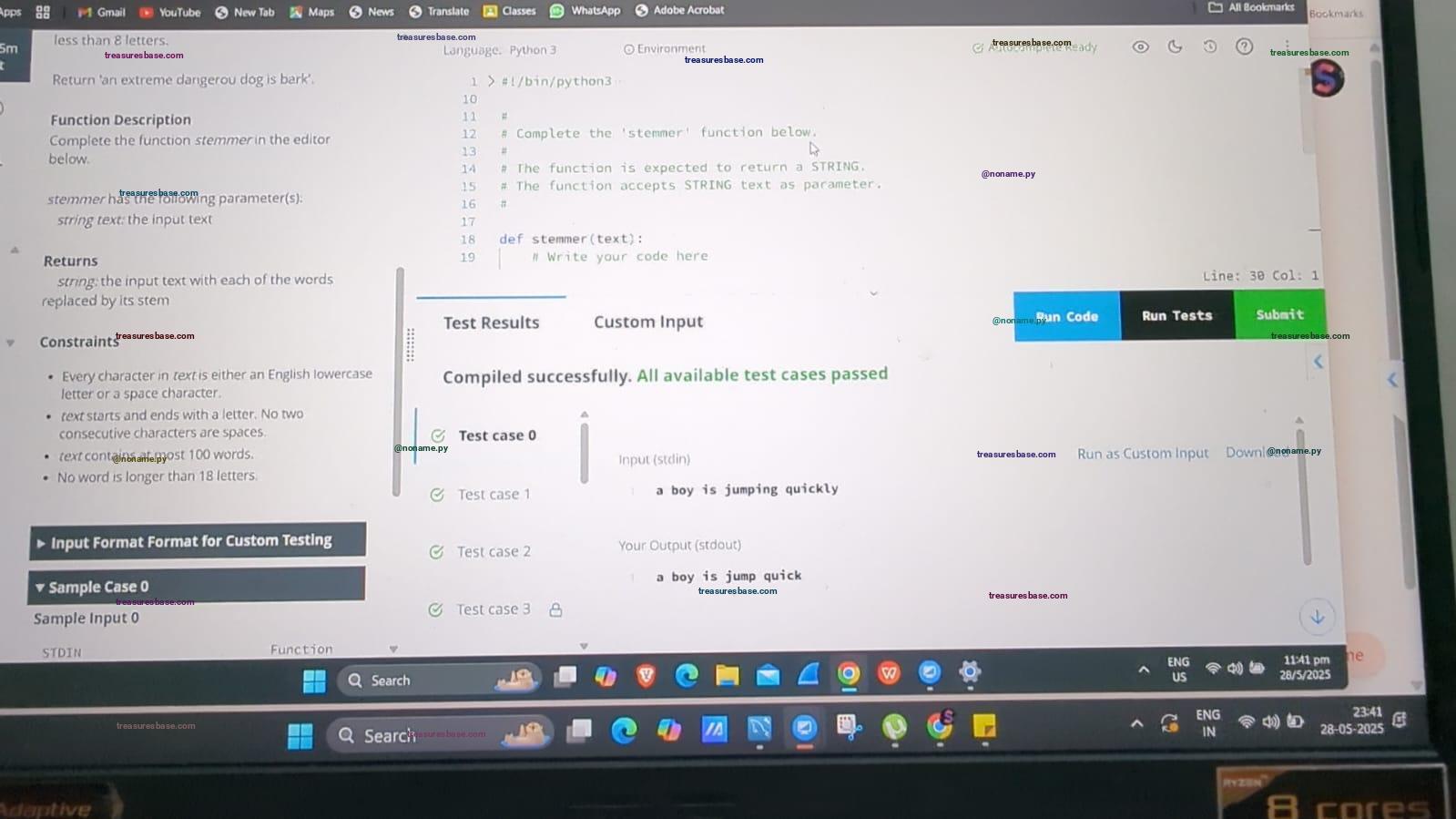
Solution
def stemmer(text):
# Write your code here
answer_array = []
words = [word for word in text.split()]
// ... rest of solution available after purchaseExplanation
```
To solve the problem of stemming words in a given string according to specific rules, start by carefully understanding the requirements and the sequence of transformations that each word must undergo. The process is straightforward, but attention to detail is important to ensure all conditions are applied correctly and in the right order.
Begin by considering the input: a string containing multiple words separated by spaces. Your goal is to process each word individually and apply the stemming rules, then reconstruct the sentence with the transformed words.
Step one is to split the input text into individual words. Since the problem guarantees no leading, trailing, or consecutive spaces, splitting by spaces will reliably isolate each word for processing.
Next, focus on the stemming algorithm itself, which consists of two primary operations applied sequentially to each word:
1. **Suffix Removal:**
Check if the word ends with any of the suffixes "ed", "ly", or "ing". If so, remove that suffix. This step transforms words like "worked" to "work", "extremely" to "extreme", and "barking" to "bark".
When checking suffixes, it's important to consider the order in which you check them. Since "ing" has three characters and "ed" and "ly" have two, starting with the longest suffix first can avoid partial matches or errors.
Also, ensure that you only remove the suffix if it is exactly at the end of the word. Partial matches within the word should not trigger removal.
After removing the suffix, the new word length might change. This can impact the next step.
2. **Length Truncation:**
After suffix removal, examine the length of the resulting word. If the word is longer than 8 letters, truncate it to its first 8 characters. This means keeping only the substring from the beginning up to the eighth character.
This step ensures words like "dangerous" (9 letters) become "dangerou" (first 8 letters).
Note that truncation only happens after suffix removal, never before.
After applying these rules, the stemmed word is ready to be collected.
Repeat the above steps for every word in the original text. Keep track of all the stemmed words in order, maintaining their sequence, so the sentence can be reconstructed correctly.
Finally, join the processed words back into a single string separated by spaces. This final string is the output.
Keep in mind some additional considerations:
- If a word does not end with any of the specified suffixes, leave it unchanged except for checking the length and truncating if necessary.
- Be mindful that removing suffixes could shorten a word to fewer than or equal to 8 letters, in which case truncation won’t be needed.
- Since the input only contains lowercase English letters and spaces, case sensitivity is not a concern.
- The constraints specify a maximum of 100 words and word lengths up to 18 characters, which is manageable with straightforward string operations.
- Pay close attention to indexing and substring extraction to avoid off-by-one errors.
- Edge cases include words that are exactly 8 letters, words shorter than the suffix length, or words where suffix removal might result in an empty string (though the problem constraints imply this might not happen, it’s good to be mindful).
- Ensure the output preserves the order and number of words as in the input, just with their stemmed forms.
By thinking about the problem step-by-step like this, you break down the task into manageable parts: splitting the input, processing each word with clear rules, and then joining the results back together. This structured approach makes the implementation straightforward and less error-prone.
```