Asked in: INFOTECH
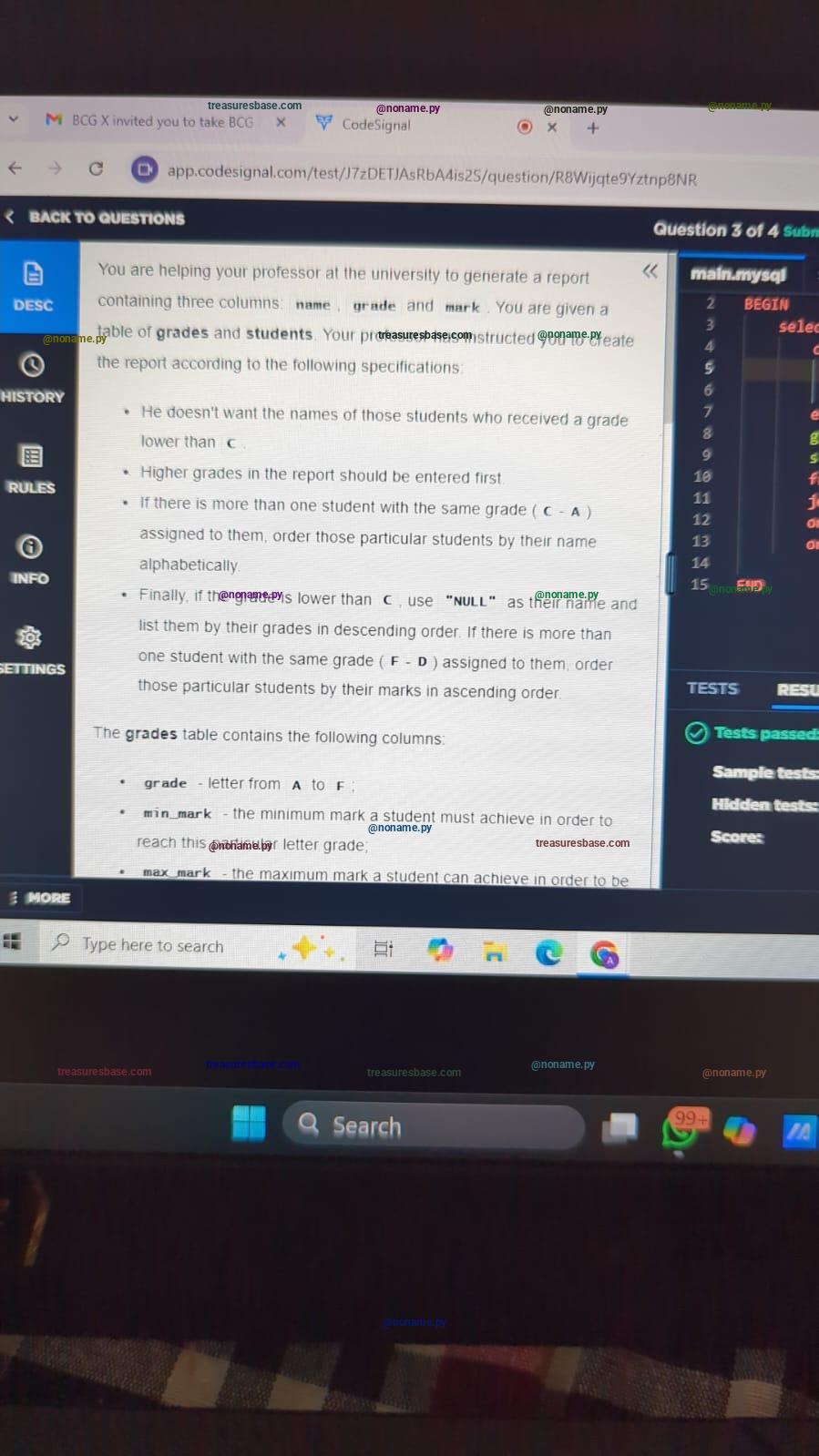
Image of the Question
All Testcases Passed ✔

Solution
select case
when g.grade <= 'C' then s.name else "NULL"
end as finalname,
g.grade,s.mark
// ... rest of solution available after purchaseExplanation
```
To approach this problem, begin by understanding the structure and relationships between the two main tables involved: the student table and the grades table. The student table likely contains fields such as student name and mark, while the grades table maps numerical mark ranges to letter grades. This implies a join or mapping operation between the two tables based on the marks to assign each student a corresponding grade.
Start by considering how to determine each student’s grade. This requires comparing a student's mark against the grade boundaries defined in the grades table. Conceptually, for each student, you need to find the grade row where the student's mark falls within the min_mark and max_mark inclusive range. This creates a derived or computed column (grade) for each student. The result is a virtual table or temporary result set that includes the student’s name, mark, and the calculated grade.
Next, break the requirements into two main branches based on the grade:
1. Students with grades of C or higher (i.e., A, B, or C)
2. Students with grades lower than C (i.e., D or F)
For the first group (grades A to C), the professor wants the student names shown. These records need to be sorted such that higher grades come first. Since the grades are letters and not inherently numerical, you will need to ensure you have a way of ordering them. One method is to use the original grades table’s ordering or assign a rank or numerical value to each grade to control the sort order. For students with the same grade, a secondary sorting criterion is required—alphabetical ordering of student names.
For the second group (grades D and F), the professor does not want student names revealed. Instead, the name field should display "NULL". For these students, you should still associate them with their correct grade, and then sort this group by grade descending (with F considered lower than D), and for students sharing the same grade, sort them by their marks in ascending order.
With these requirements clear, the next step is to think about how to construct a query or data transformation that performs this mapping and filtering. Consider filtering and labeling students into two separate result sets:
- One containing students with grades A to C and real names
- Another with grades D to F and names replaced with NULL
Then consider how to unify both result sets into one cohesive output. This means thinking in terms of combining two datasets (one with names, one with NULLs) while preserving the required ordering. This implies use of a union operation or similar, ensuring that both sets have consistent column formats (i.e., name, grade, and mark), even if some fields contain NULLs conditionally.
After merging the two datasets, apply a final sort that considers both the grade’s priority and secondary conditions (name or mark ordering, depending on the group). To do this, you might need to associate each grade with an explicit ordering value to sort reliably. This can be done by referencing the grade table again or using a mapping structure that provides a numeric weight to each letter grade.
Throughout this process, avoid directly manipulating the letter grades in ways that assume alphabetical order corresponds with performance level, as this is not always reliable (e.g., 'A' is better than 'B', but 'F' comes before 'D' alphabetically). Instead, always rely on the defined grade boundaries or create explicit grade priority values to sort accurately.
Finally, ensure that the result set includes exactly the required three columns—name, grade, and mark—in the exact formatting and content structure described. Pay attention to the rules about NULL values for names and the multiple sort conditions for each subgroup of students. This kind of problem is a good example of conditional logic, data transformation, and careful sorting, so focus on breaking it down into smaller, verifiable steps to ensure accuracy.
```